Introduction
This is the demo website for the paper, “A Benchmarking Initiative for Audio-domain Music Generation using the FreeSound Loop Dataset”, which is accepted for publication by ISMIR2021. The work was done by Tun-Min Hung, Bo-Yu Chen, Yen-Tung Yeh, and Yi-Hsuan Yang.
In this webpage, we provide audio examples of the one-bar drum loops (with 120 BPM) generated by different generative models, including UNAGAN, StyleGAN, and StyleGAN2.
We first show the result for the models trained on the drum-loop subset of the FreeSound Loop Dataset (i.e., the Freesound dataset). Then, we show the result for the models trained on the larger, yet private, looperman dataset.
We also show the result when we use the style-mixing technique of StyleGAN2 to generate the “interpolated” version of a source loop and a target loop, in a “style transfer” like flavor.
Demo audio
Models trained on the Freesound dataset
- real data






- UNAGAN






- StyleGAN

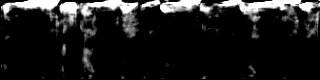
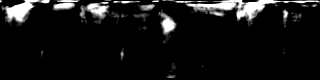



- StyleGAN2




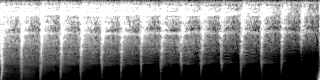

Interpolation result of the StyleGAN2 model trained on the Freesound dataset
StyleGAN and StyleGAN2 show fascinating results in their style mixing experiments. These models generate images from a coarse-to-fine manner, and it appears that the early coarse-style blocks control more of the generation of high-level visual attributes, such as pose and hairstyle, while the later fine-style blocks control the generation of finer visual attributes such as color and lightning. The style-mixing experiment shows that we can interchange the style codes to the coarse-style and fine-style blocks of two input images A and B, and create the interpolated version whose high-level features come from one of the input images and low-level features from the other.
Being inspired by this, we also conduct style-mixing using the StyleGAN2 model we trained. Specifically, we consider the first two blocks of our model as the coarse-style blocks, and the last two blocks as the fine-style blocks. According to the interpolated result shown below, it seems the interpolated loop resembles the source audio in terms of timbre, and resembles the target audio in its rhythmic pattern.

| source_1 | source_2 | source_3 | source_4 | source_5 | |
| target_1 | |||||
| target_2 | |||||
| target_3 |
Models trained on the Looperman dataset
- real data






- UNAGAN






- StyleGAN

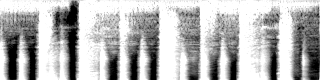


- StyleGAN2





- StyleGAN2_four_bar






Interpolation result of the StyleGAN2 model trained on the Looperman dataset with one bar

| source_1 | source_2 | source_3 | source_4 | source_5 | |
| target_1 | |||||
| target_2 | |||||
| target_3 |
Interpolation result of the StyleGAN2 model trained on the Looperman dataset with four bar

| source_1 | source_2 | source_3 | |
| target_1 | |||
| target_2 | |||
| target_3 |